Document Corpora, Document Source and Destination¶
Corpora are collections of documents and in GateNLP, there are three classes which represent collections of documents:
- Corpus: this is any object that behaves like a list or array of documents and allows to get and set the nth document via
mycorpus[n]andmycorpus[n] = doc. A Python list can thus be used as a Corpus, but GateNLP provides other Corpus classes for getting and saving documents from/to a directory and other storage locations. - DocumentSource: this is something that can be used as an iterator over documents. Any iterable of documents can be used as DocumentSource, but GateNLP provides a number of classes to iterate over documents from other sources, like the result of a database query.
- DocumentDestination: this is something where a document can be added to by invoking the
addorappendmethod.
Corpus and DocumentSource objects can be processed by an executor (see Processing)
# All new files used in this notebook will get created in directory tmp
import os
if not os.path.exists("tmp"):
os.mkdir("tmp")
List Corpus¶
A list corpus makes it possible to use any Python list-like object as a corpus.
from gatenlp import Document
# Create a list of documents from a list of texts
texts = [
"This is the first text.",
"Another text.\nThis one has two lines",
"This is the third document.\nIt has three lines.\nThis line is the last one.\n",
"And another document."
]
docs = [Document(t) for t in texts]
# Create the List corpus
from gatenlp.corpora import ListCorpus
lcorpus = ListCorpus(docs)
len(lcorpus)
4
# all corpus instances allow to access and set elements and get the length
lcorpus[2] = Document("some other document")
print(len(lcorpus))
lcorpus[3]
4
# corpus instances also have the store method which allows to store back a document that was
# fetched from the corpus without knowing its index. This is accomplished by storing the index it was
# retrieved from in a hidden document feature
doc = lcorpus[2]
print(doc.features[lcorpus.idxfeatname()])
lcorpus.store(doc) # store back the document
# NOTE: since this ListCorpus is wrapping an in-memory list, any change to the document is reflected
# in the corpus anyways, so storing back of a changed document is not necessary here. The code above
# serves as an illustration for how this works with corpus classes where the documents are read/saved
# somewhere else.
2
# Some corpus classes also implement the append() method which allows to add additional documents
# to the corpus (just like it is possible to add elements to a list)
# However, this is limited to specific corpus implementations and only allows appending to the end of the corpus
lcorpus.append(Document("Another new document"))
print(len(lcorpus))
5
BdocjsLinesFileSource and BdocjsLinesFileDestination¶
This document source reads the JSON bdoc representation of a document from each line in an input file and produces the corresponding documents. When a gatenlp Document is saved as "json", i.e. in bdoc json format, all json is in a single line since any newline character gets escaped in the json representation.
This makes it possible to store several documents in a single text file by having one json-serialization per row.
Document sources¶
A document source provides sequential access to documents, similar to reading lines from a file. All document sources are iterable and are also context managers so they can be used using this pattern:
with SomeDocumentSource(parms...) as src:
for doc in src:
dosomethingwith(doc)Document destinations¶
A document destination allows to write documents similar to writing lines to a file. All document destinations are context managers so they can be used using this pattern:
with SomeDocumentSource(parms...) as dest:
for doc in somedocuments:
dest.append(doc)# lets first save the in-memory ListCorpus as a single JSONL file using the JsonBdocjsLinesFileDestination
from gatenlp.corpora import BdocjsLinesFileSource, BdocjsLinesFileDestination
bdocjsfile = os.path.join("tmp", "bdocjsfile.json")
with BdocjsLinesFileDestination(bdocjsfile) as bdocjsdest:
for doc in lcorpus:
bdocjsdest.append(doc)
# now lets test reading that file to iterate over the documents
with BdocjsLinesFileSource(bdocjsfile) as bdocjssrc:
for doc in bdocjssrc:
print(doc.text)
This is the first text. Another text. This one has two lines some other document And another document. Another new document
DirFilesSource, DirFilesDestination, DirFilesCorpus¶
The DirFilesSource is a document sorce that imports/reads files in a directory or directory tree as one iterates over the source.
The DirFilesDestination is a destination that creates files in a directory as documents get appended to the destination.
The DirFilesCorpus is a corpus that accesses stored documents in a directory or directory tree when accessing the corpus element and stores them back to their file when assigning the corpus element.
Let's first convert the jsonlines file we have created into a directory corpus. A directory files corpus allows for several different ways of how to name the files or file paths within the directory. Here we simply use the index of the document, i.e. the running number of the document as the base name of the created file:
import os
from gatenlp.corpora import DirFilesSource, DirFilesDestination, DirFilesCorpus
dir1 = os.path.join("tmp", "dir1")
if not os.path.exists(dir1):
os.mkdir(dir1) # The directory for a DirFilesDestination must exist
# The path_from="idx" setting makes the DirFilesCorpus use the running number of the document as
# the file base name.
with BdocjsLinesFileSource(bdocjsfile) as src:
with DirFilesDestination(dir1, ext="bdocjs", path_from="idx") as dest:
for doc in src:
dest.append(doc)
# lets see what the content of the directory is now:
print(os.listdir(dir1))
['1.bdocjs', '3.bdocjs', '2.bdocjs', '4.bdocjs', '0.bdocjs']
Now that we have a directory with files representing documents, we can open it as a document source or corpus.
If we open it as a document source, we can simply iterate over all documents in it:
with DirFilesSource(dir1) as src2:
for doc in src2:
print(doc)
Document(Another text.
This one has two lines,features=Features({'_relpath': '1.bdocjs'}),anns=[])
Document(And another document.,features=Features({'_relpath': '3.bdocjs'}),anns=[])
Document(some other document,features=Features({'_relpath': '2.bdocjs'}),anns=[])
Document(Another new document,features=Features({'_relpath': '4.bdocjs'}),anns=[])
Document(This is the first text.,features=Features({'_relpath': '0.bdocjs'}),anns=[])
If we open it as a document corpus, we can directly access each document as from a list or an array:
corp1 = DirFilesCorpus(dir1)
# we can get the length
print("length is:", len(corp1))
# we can iterate over the documents in it:
print("Original documents:")
for doc in corp1:
print(doc)
# but we can also update each element which will save the corresponding document to the original
# file in the directory where it was loaded from. Here we add an annotation and document feature
# to each document in the corpus.
for idx, doc in enumerate(corp1):
doc.features["docidx"] = idx
doc.annset().add(0,3,"Type1")
corp1[idx] = doc # !! this is what updates the document file in the directory
# the files in the directory now contain the modified documents. lets open them again and show them
# using a dirfiles source:
src3 = DirFilesSource(dir1)
print("Updated documents:")
for doc in src2:
print(doc)
length is: 5
Original documents:
Document(Another text.
This one has two lines,features=Features({'__idx_139813269566096': 0}),anns=[])
Document(And another document.,features=Features({'__idx_139813269566096': 1}),anns=[])
Document(some other document,features=Features({'__idx_139813269566096': 2}),anns=[])
Document(Another new document,features=Features({'__idx_139813269566096': 3}),anns=[])
Document(This is the first text.,features=Features({'__idx_139813269566096': 4}),anns=[])
Updated documents:
Document(Another text.
This one has two lines,features=Features({'docidx': 0, '_relpath': '1.bdocjs'}),anns=['':1])
Document(And another document.,features=Features({'docidx': 1, '_relpath': '3.bdocjs'}),anns=['':1])
Document(some other document,features=Features({'docidx': 2, '_relpath': '2.bdocjs'}),anns=['':1])
Document(Another new document,features=Features({'docidx': 3, '_relpath': '4.bdocjs'}),anns=['':1])
Document(This is the first text.,features=Features({'docidx': 4, '_relpath': '0.bdocjs'}),anns=['':1])
Viewing and browsing a Corpus¶
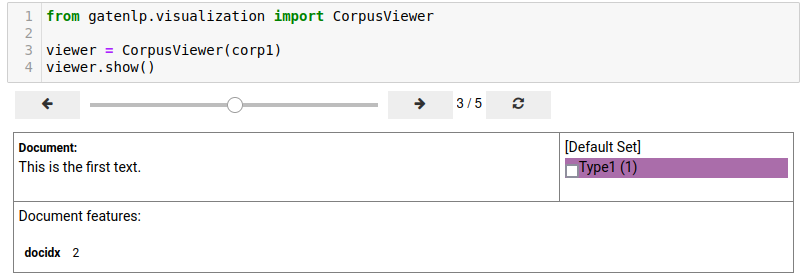
Corpus instances can be viewed in a notebook using the CorpusViewer class. Note that other than the document viewer, the corpus viewer needds a notebook connected to jupyter since the widgets of the viewer interact with the python kernel to fetch documents from the corpus.
Note: the widgets used for the CorpusViewer do not get converted properly from the notebook to Markdown and may not be visible below. To also show what the viewer looks like we also include a screenshot of the viewer interface below.
from gatenlp.visualization import CorpusViewer
viewer = CorpusViewer(corp1)
viewer.show()
CorpusViewer Screenshot¶
JsonLinesFileSource and JsonLinesFileDestination¶
This document source reads JSON from each line in an input file and uses one field as the text of the document, and arbitrary other fields to store as document features or hidden (for saving later).
The document destination writes the document text or bdocjs representation to one field in each output JSON line and optionally also writes json fields from the document features.
import json
from gatenlp.corpora import JsonLinesFileDestination, JsonLinesFileSource
# lets first create a JSONL file
jsonlfile = os.path.join("tmp", "jsonlfile.json")
data = [
dict(text="this is some text", f1=12, f2="some string"),
dict(text="another text", f1=3, f2="also a string"),
]
with open(jsonlfile, "wt") as outfp:
for j in data:
print(json.dumps(j), file=outfp)
# Read the JSONL and convert the text to a document, and store all other fields as document features
docs = [] # save documents in there for later
with JsonLinesFileSource(jsonlfile, text_field="text", feature_fields=["f1"], data_fields=["f2"]) as src:
for doc in src:
print(doc)
docs.append(doc)
Document(this is some text,features=Features({'f1': 12, '__data': {'f2': 'some string'}}),anns=[])
Document(another text,features=Features({'f1': 3, '__data': {'f2': 'also a string'}}),anns=[])
# similarly, a sequence of documents can be written to a JSON lines file by saving the text into
# some field and (selected) document features to other fields
with JsonLinesFileDestination(
jsonlfile, text_field="text", feature_fields=["f1"], data_fields=["f2"], data_feature=None) as dest:
for doc in docs:
dest.append(doc)
with open(jsonlfile, "rt") as infp:
for l in infp:
print(l, end="")
{"f1": 12, "f2": "some string", "text": "this is some text"}
{"f1": 3, "f2": "also a string", "text": "another text"}
# However, by default, if data_features is not set to None, all fields other than the text field
# get saved in a hidden feature "__data" from where those fields get written back to json by default
# with the JsonLinesFileDestination:
docs = [] # save documents in there for later
with JsonLinesFileSource(jsonlfile, text_field="text", data_fields=True) as src:
print("Documents:")
for doc in src:
print(doc)
docs.append(doc)
with JsonLinesFileDestination(jsonlfile, text_field="text", data_fields=True) as dest:
for doc in docs:
dest.append(doc)
with open(jsonlfile, "rt") as infp:
print("JSON lines:")
for l in infp:
print(l, end="")
Documents:
Document(this is some text,features=Features({'__data': {'f1': 12, 'f2': 'some string'}}),anns=[])
Document(another text,features=Features({'__data': {'f1': 3, 'f2': 'also a string'}}),anns=[])
JSON lines:
{"f1": 12, "f2": "some string", "text": "this is some text"}
{"f1": 3, "f2": "also a string", "text": "another text"}
TsvFileSource¶
The TsvFileSource is a document source which initializes documents from the text in some column of a tsv file and optionally sets document features from other columns of the tsv file.
# Let's load documents from a tsv file on a web page. This tsv file has three columns and a header line which
# gives the names "text", "feat1" "feat2" to the columns.
# We create the documents by fetching the text from column "text" and creating two document features
# with names "f1" and "f2" from the columns "feat1" and "feat2":
from gatenlp.corpora import TsvFileSource
tsvsrc = TsvFileSource("https://gatenlp.github.io/python-gatenlp/tsvcorpus_example1.tsv",
text_col="text", feature_cols=dict(f1="feat1", f2="feat2"))
for doc in tsvsrc:
print(doc)
Document(Here is some text. Like with JSON, newlines are escaped:\nHere is another line.,features=Features({'f1': 'fval1', 'f2': 'fval2'}),anns=[])
Document(Another text\nThis one\nhas more\n\nlines.,features=Features({'f1': '11', 'f2': '22'}),anns=[])
Document(And another.,features=Features({'f1': 'a', 'f2': 'b'}),anns=[])
# clean up after ourselves
#import shutil
#shutil.rmtree("tmp")
Notebook last updated¶
import gatenlp
print("NB last updated with gatenlp version", gatenlp.__version__)
NB last updated with gatenlp version 1.0.8a1